Apasih Metodologi Data Science?
Metodologi data science adalah langkah-langkah digunakan dalam proyek data science
agar dapat menghasilkan hasil yang optimal yang dapat menjawab pertanyaan dari suatu masalah
yang ingin diselesaikan. Metodologi ini tidak bergantung pada teknologi atau tools tertentu. Secara umum terdapat dua kelompok metodologi, metodologi teknis dan metodologi bisnis.
Berbagai Metodologi Data Science
Terdapat 2 jenis Metodologi didalam data science, yaitu metodologi kegiatan teknis dan
metodologi kegiatan bisnis (dan teknis) yang disebut juga metodologi lengkap. Dalam Metodologi
teknis ada 2 contoh diantaranya Metodologi Knowledge Discovery and data Mining (KDD) dan
Metodologi Sample, Emplore, Modify, Model dan Assess (SEMMA). Dan untuk metodologi
lengkap beberapa contoh diantaranya: Cross-Industry Standard Process for Data Mining (CRISPDM), IBM Data Science Methodology, Microsoft’s Team Data Science Process, dan Domino
DataLab Methodology.
Jenis Metodologi Kegiatan Teknis
1. Knowledge Discovery dan Data Mining (KDD)
Knowledge Discovery in Database Process (KDD) adalah salah satu metode yang bisa digunakan
dalam melakukan data mining.
KDD sebagai proses dari
Fayyed et al. (1996)
menggunakan metode data mining untuk mencari informasi-informasi yang berharga, pola yang
ada di dalam data, yang melibatkan algoritma untuk mengidentifikasi pola pada data.
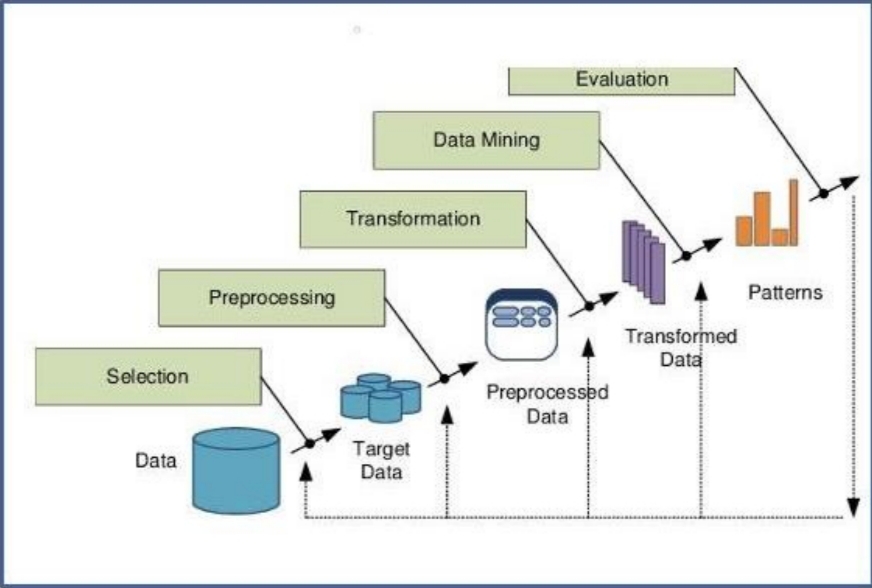
KDD merupakan proses pemanfaatan metoda Data Mining untuk mengekstraksi pengetahuan sesuai dengan ukuran atau threshold yang ditentukan. Proses dimulai dengan adanya sekumpulan data (dataset) yang akan mengalami serangkaian proses sebagai berikut:
- Selection: Pemilihan data (data target) yang akan menjadi sampel untuk prosesselanjutnya.
- Preprocessing data: Melakukan serangkaian proses untuk melengkapi data danmenjaga
konsistensi data. - Transformation: Mengubah representasi data untuk mempermudah danmemperbaiki agar
sesuai dengan Teknik data mining yang akan dipergunakan. - Data Mining: Kegiatan pengembangan model untuk mencari pola dari data yangdiberikan
- Evaluation: Proses interpretasi dan evaluasi pola yang diperoleh apakah pola yang menarik, berguna atau relevan.
2. Sample, Emplore, Modify, Model dan Assess (SEMMA)
SEMMA merupakan singkatan dari Sample, Emplore, Modify, Model, dan Assess. Metode
ini dapat ditemukan oleh SAS Institute yang dapat digunakan untuk memudahkan penggguna
untuk memprediksi tentang variable-variabel yang mengacu melakukan proses sebuah proyek data
mining. Proses data mining SEMMA dapat digunakan dengan mudah dan mudah dipahami proses yang terkait dalam pemeliharaan proyek data mining. Proses data mining SEMMA memiliki 5 proses tahapan yaitu Sample, Explore, Modify, Model, dan Assess, dari masing-masing tersebut
memiliki peran sendiri dalam proses data mining dan memiliki manfaat dalam proses data mining
tersebut.
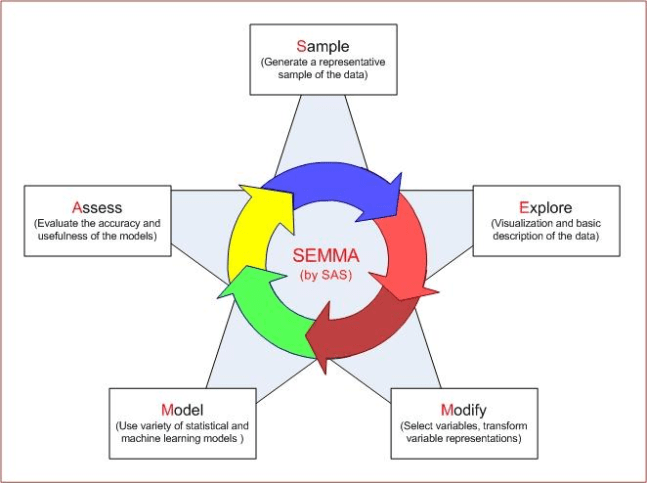
Sementara metodologi SEMMA sesuai dengan namanya melakukan serangkaian kegiatan yang
bersifat siklik (berulang) yaitu:
- Sample: Proses ekstraksi data untuk mendapatkan dataset yang cukup untuk mendapatkan
informasi signifikan namun tidak terlalu besar sehingga mudah untuk diproses selanjutnya. - Explore: Proses untuk mengeksplorasi data dengan mencari trend dan anomali untuk
mendapatkan pemahaman tentang data - Modify: Proses modifikasi data dengan membuat, memilih dan transformasi variable untuk proses pemodelan.
- Model: Proses pemodelan dari data dengan mencari secara otomatis kombinasi data yang
dapat dipakai untuk prediksi - Assess: Mengevaluasi pola yang ditemukan apakah berguna dan cukup andal.
Jenis Metodologi Kegiatan Bisnis
1. Cross-Industry Standard Process for Data Mining (CRISP-DM)
Cross-Industry Standard Process for Data Mining atau CRISP-DM adalah salah satu model proses data mining (datamining framework) yang awalnya (1996) dibangun oleh 5 perusahaan yaitu Integral Solutions Ltd (ISL), Teradata, Daimler AG, NCR Corporation dan OHRA. Framework ini kemudian dikembangan oleh ratusan organisasi dan perusahaan di Eropa untuk dijadikan methodology standard non-proprietary bagi data mining.
Tahapan proses dalam CRISP-DM ada 6 tahapan yang bersifat adaptif dan terurut. Dimana output dari setiap tahapan yang ada dalam metode ini saling mempengaruhi satu sama lain, dalam
(Ginantara et al. 2021).
kata lain tahap sebelumnya akan mempengaruhi tahap selanjutnya yang ada dalam proses CRISP-DM
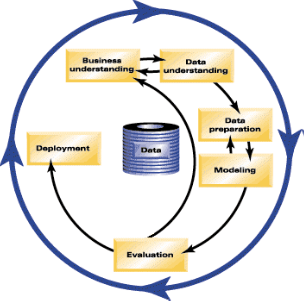
Masing-masing tahapan CRISP-DM tersebut dijelaskan sebagai berikut:
- Business Understanding: Kegiatan yang dilakukan antara lain: menentukan tujuan dan persyaratan dengan jelas secara keseluruhan, menerjemahkan tujuan tersebut serta menentukan pembatasan dalam perumusan masalah data mining, dan selanjutnya mempersiapkan strategi awal untuk mencapai tujuan tersebut.
- Data Understanding: Secara garis besar untuk memeriksa data, sehingga dapat
mengidentifikasi masalah dalam data. Tahap ini memberikan fondasi analitik untuk sebuah
penelitian dengan membuat ringkasaan (summary) dan mengidentifikasi potensi masalah dalam data. - Data Preparation: Secara garis besar untuk memperbaiki masalah dalam data, kemudian
membuat variabel derived. Tahap sampling dapat dilakukan disini dan data secara umum dibagi menjadi dua, data training dan data testing. Kegiatan yang dilakukan antara lain:
memilih kasus dan parameter yang akan dianalisis (Select Data), melakukan transformasi
terhadap parameter tertentu (Transformation), dan melakukan pembersihan data agar data siap
untuk tahap modeling (Cleaning). - Modeling: Secara garis besar untuk membuat model prediktif atau deskriptif. Pada tahap ini
dilakukan metode statistika dan Machine Learning untuk penentuan terhadap teknik data mining, alat bantu data mining, dan algoritma data mining yang akan diterapkan. Lalu selanjutnya adalah melakukan penerapan teknik dan algoritma data mining tersebut kepada data dengan bantuan alat bantu. Jika diperlukan penyesuaian data terhadap teknik data mining tertentu, dapat kembali ke tahap data preparation. Beberapa modeling yang biasa dilakukan adalah classification, scoring, ranking, clustering, finding relation, dan characterization. - Evaluation: Melakukan interpretasi terhadap hasil dari data mining yang dihasilkan dalam
proses pemodelan pada tahap sebelumnya. Evaluasi dilakukan terhadap model yang
diterapkan pada tahap sebelumnya dengan tujuan agar model yang ditentukan dapat sesuai dengan tujuan yang ingin dicapai dalam tahap pertama. - Deployment: Perencanaan untuk Deployment dimulai selama Business Understanding dan
harus menggabungkan tidak hanya bagaimana untuk menghasilkan nilai model, tetapi juga bagaimana mengkonversi skor keputusan, dan bagaimana untuk menggabungkan keputusan dalam sistem operasional.
2. IBM Data Science
Tujuan dari metodologi data science adalah untuk berbagi metodologi yang dapat digunakan dalam data science, untuk memastikan bahwa data yang digunakan dalam pemecahan masalah adalah relevan dan dimanipulasi dengan benar untuk menjawab pertanyaan.
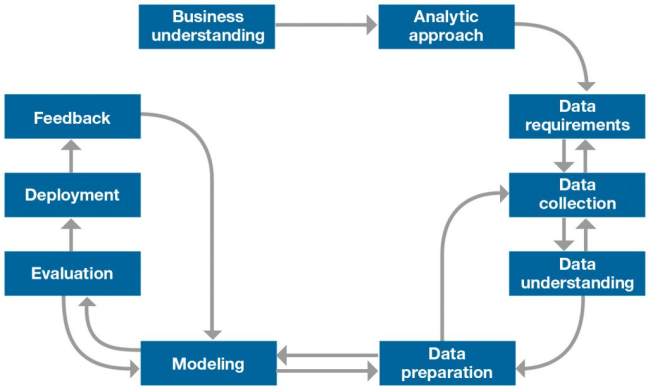
Alur kerja dari Data Scientist adalah sebagai berikut:
- Business Understanding: memahami apakah tujuan bisnis untuk meningkatkan efisiensi
kegiatan atau untuk menambah jenis kegiatan. Setelah tujuan diklarifikasi, langkah
selanjutnya adalah mencari tahu kira-kira apa saja yang bisa mendukung tujuan. - Analytic Understanding: Berdasarkan pemahaman bisnis sebelumnya, kita harus
memutuskan pendekatan analitis mana yang harus diikuti, yaitu: - Deskriptif → status saat ini dan informasi yang diberikan.
- Diagnostik → analisis statistik, apa yang terjadi dan mengapa itu terjadi.
- Prediktif → meramalkan tren atau kemungkinan kejadian di masa depan.
- Preskriptif → bagaimana masalah harus diselesaikan.
- Data Requirements: Metode analisis yang telah dipilih sebelumnya menunjukkan isi,
format, dan sumber data yang diperlukan untuk dikumpulkan. Selama proses kebutuhan data, kita harus menemukan jawaban atas pertanyaan-pertanyaan seperti apa, dimana, kapan, mengapa, bagaimana, siapa. - Data Collenction: Data yang dikumpulkan dapat diperoleh dalam format acak, selanjutnya data yang dikumpulkan harus divalidasi. Dengan demikian, jika diperlukan, seseorang dapat mengumpulkan lebih banyak data atau membuang data yang tidak relevan.
- Data Understanding: mengumpulkan data berdasarkan masalah yang akan
dipecahkan. Statistik perlu digunakan untuk memastikan apakah ada nilai yang hilang atau tidak. Terkadang nilai yang hilang bisa berarti “0” atau “tidak” atau bahkan “tidak
diketahui”. - Data Preparation: melakukan pembersihan data dan pemilihan data.
- Modelling: Pada tahap ini Data Scientist menentukan apakah data yang disiapkan sudah sesuai atau membutuhkan lebih banyak finishing dan bumbu. Ilmuwan data memiliki kesempatan untuk mengambil sampel data dan fokus pada pengembangan model deskriptif atau prediktif.
- Evaluation: Evaluasi model dilakukan selama proses pengembangan model. Di sini Data
Scientist memeriksa kualitas model apakah memenuhi persyaratan yang diberikan oleh
stakeholder atau tidak. - Deployment: Setelah Data Scientist mendapatkan model terbaik untuk pemecahan masalah bisnis, akan bermanfaat jika stakeholder dapat menggunakannya. Oleh karena itu, tahap setelah evaluasi adalah implementasi dan pengujian akhir. Pada tahap ini, Data Scientist akan bekerja sama dengan para backend dan frontend engineer untuk mengimplementasikan model yang telah dibuat agar mudah digunakan oleh para stakeholder.
- Feedback: Setelah proses penyebaran model, stakeholder akan mendapatkan feedback
tentang kinerja model. Menganalisis umpan balik memungkinkan Data Scientist untuk
menyempurnakan model dan meningkatkan akurasi dan kegunaannya.
3. Microsoft’s Team Data Science Process
Proses Data Science Tim (TDSP) adalah metodologi data science yang tangkas dan berulang untuk memberikan solusi analisis prediktif dan aplikasi cerdas secara efisien. TDSP membantu meningkatkan kolaborasi dan pembelajaran tim dengan menyarankan bagaimana peran-peran tim dapat bekerja bersama dengan semaksimal mungkin. TDSP mencakup praktik dan struktur terbaik dari Microsoft dan para pemimpin industri lainnya untuk membantu keberhasilan implementasi inisiatif data science. Tujuannya adalah untuk membantu perusahaan sepenuhnya
mendapatkan manfaat dari program analitik mereka.
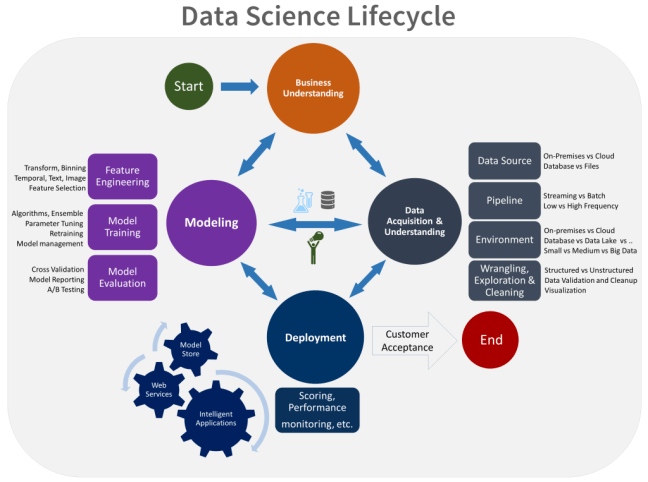
Metodologi lain adalah dari Microsoft. Sama dengan sebelumnya, proses diawali dengan kegiatan Business Understanding. Daftar proses utamanya adalah sebagai berikut:
- Business Understanding : Kegiatan untuk memahami masalah yang dihadapi.
- Data Acquisition and Understanding : Kegiatan yang meliputi proses pengumpuilan dan eksplorasi data. Data bisa diambil dari data internal (on promise) ataupun dari cloud dan bisa berupa database ataupun file flat. Proses dilakukan melalui pipeline, yang dapat berupa proses batch atau streaming. Eksplorasi (data wrangling) meliputi pembersihan data, validasi dan visualisasi.
- Modeling : Pengembangan model yang meliputi feature engineering, model fitting, dan model evaluation.
- Deployment : Pemasangan model ke dalam aplikasi intelijen, suatu web service atau objek
pada model store. Proses diakhiri dengan UAT (Customer Acceptance). - Domino DataLab : Domino Data Lab mengubah cara kerja tim ilmu data, menghadirkan Platform Ilmu Data Perusahaan yang mempercepat penelitian dan meningkatkan kolaborasi. Ilmuwan data mendapat manfaat dari akses ke sumber daya komputasi yang kuat, fitur untuk membuat pekerjaan mereka lebih efisien, dan alat untuk mempublikasikan hasil dan menerapkan model dengan cepat untuk orang lain. Tim ilmu data mendapatkan hub pusat untuk berkolaborasi dan berbagi, membangun praktik terbaik, dan belajar dari satu sama lain. Berbasis di San Francisco, pelanggan Domino berkisar dari perusahaan rintisan kecil hingga perusahaan Fortune 500.
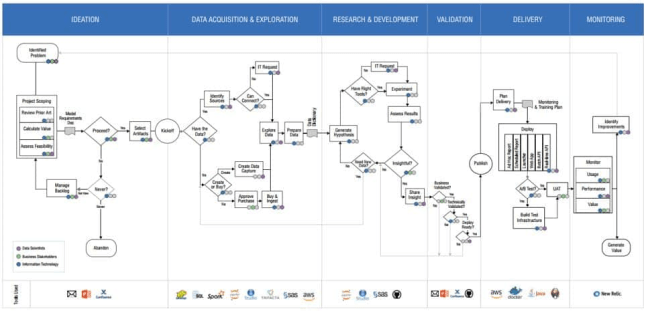
Proses utama pada metodologi ini adalah:
- Ideation adalah pemahaman terhadap masalah pada proses bisnis serta identifikasi objektif bisnisnya. Langkah berikutnya adalah melakukan perhitungan terhadap objektif bisnis tersebut beserta Cost-Benefit Analysis.
- Data Acquisition and Preparation: Menentukan data yang diperlukan baik yang berasal dari sistem internal ataupun eksternal. Setelah proses akuisisi dilakukan eksplorasi terhadap data dan juga proses persiapan data.
- Research and Development: Pemodelan dilakukan sebagai suatu kegiatan pembuktian
hipotesa dan pemodelan. Jika hasil sudah dianggap cukup makadilakukan kegiatan berikutnya sementara jika belum dilakukan perbaikan data atau perubahan hipotesa. Dalam proses eksperimen, selaain metrik statistic dipergunhakan juga KPI organisasi. - Validation: Model yang sudah dibuat divalidasi dari sudut bisnis dan teknis sebelum dipasang (deployment)
- Delivery: Deployment yang dimulai dengan perencanaan, lalu pemasangan dan perawatan sistem.Dalam proses ini juga dilakukan UAT (User Acceptance Testing).
5. Metodologi dari Domino (Domino DataLab Methodology).
Metodologi Domino juga dilengkapi daftar personal yang terlibat pada setiap langkah baikdata
scientist, business people, dan petugas Information technology Division. Juga dilengkapi daftar
tools yang bisa dipergunakan dalam setiap langkah metodologi.
Proses Pembandingan Langkah antara berbagai Metodologi
Metodologi data science adalah kerangka kerja atau framework yang membantu para profesional data science dalam memandu proses bisnis dan analisis data. Setiap metodologi memiliki ujuan akhir yang sama yaitu untuk menghasilkan pemahaman yang mendalam dan prediksi akurat tentang data, tetapi memiliki pengertian dan tahapan proses yang berbeda.
Berikut ini perbandingan langkah antara berbagai metodologi, yaitu:
1. KDD (Knowledge Discovery in Databases) : Metodologi ini digunakan untuk mengidentifikasi pola dalam data dan menemukan informasi baru dari data yang ada. Metodologi ini terdiri dari 5 tahap yaitu: Selection, Pre-processing, Transformation, Data Mining, Interpretation/Evaluation
2. SEMMA (Sample, Explore, Modify, Model, Assess) : Metodologi ini digunakan untuk mengeksplorasi data dan membangun model prediksi berdasarkan data yang tersedia. Metodologi ini terdiri dari 5 tahap yaitu: Sample, Explore, Modify, Model, Assess
3. CRISP-DM (Cross-Industry Standard Process for Data Mining) : Metodologi ini digunakan untuk mengatasi masalah dalam pengolahan data dan menemukan solusi yang tepat untuk masalah tersebut. Metodologi ini terdiri dari 6 tahap yaitu: Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation, Deployment
4. Metodologi IBM Data Science : Metodologi ini berfokus pada pemecahan masalah bisnis dengan menggunakan data. Metodologi ini terdiri dari 14 tahap yaitu: Business Understanding, Analytic Understanding, Deskriptif, Diagnostik, Prediktif, Preskriptif, Data Requirements, Data Collenction, Data Understanding, Data Preparation, Modelling, Evaluation, Deployment, Feedback.
5. Microsoft’s Team Data Science Process : Metodologi ini berfokus pada kerja tim dan kolaborasi dalam proses data science. Metodologi ini terdiri dari 5 tahap yaitu: Business Understanding, Data Acquisition and Understanding, Modeling, Deployment dan Domino DataLab
6. Domino DataLab : Metodologi ini digunakan untuk mempercepat penelitian dan meningkatkan kolaborasi. Metodologi ini terdiri dari 5 tahap yaitu Ideation, Data Acquisition and Understanding, Research and Development, Validation, dan Delivery.
Faktor kesuksesan dan kegagalan pada tahapan generik metodologi data science
Metodologi data science memiliki beberapa tahapan, salah satunya adalah tahap genetik yang mencakup pemilihan fitur atau variabel penting untuk digunakan dalam analisis data. Faktor kesuksesan dan kegagalan pada tahapan genetik ini antara lain:
Faktor Kesuksesan:
- Pemilihan fitur yang tepat: Dalam tahap genetik, pemilihan fitur yang tepat sangat penting untuk memastikan kualitas analisis data. Fitur-fitur yang dipilih harus relevan dengan tujuan analisis data dan harus memiliki nilai yang tinggi dalam memberikan informasi yang berguna.
- Penggunaan algoritma yang tepat: Pada tahap genetik, algoritma yang digunakan untuk memilih fitur juga penting. Algoritma yang tepat dapat membantu dalam menghasilkan fitur-fitur yang memiliki korelasi tinggi dengan variabel target dan menghilangkan fitur-fitur yang tidak relevan.
- Pengolahan data yang benar: Data yang tidak diproses dengan benar dapat menghasilkan fitur-fitur yang tidak relevan atau bahkan menghasilkan hasil analisis yang salah. Oleh karena itu, pengolahan data yang benar sangat penting untuk tahap genetik.
Faktor Kegagalan:
- Kurangnya pemahaman terhadap data: Kurangnya pemahaman tentang data yang dianalisis dapat menyebabkan kesalahan dalam pemilihan fitur. Ini dapat menghasilkan fitur-fitur yang tidak relevan atau bahkan tidak terkait dengan variabel target.
- Penggunaan algoritma yang tidak tepat: Penggunaan algoritma yang tidak tepat dapat menyebabkan kesalahan dalam pemilihan fitur. Algoritma yang salah dapat menghasilkan fitur-fitur yang tidak relevan atau tidak terkait dengan variabel target.
- Kurangnya keterampilan dalam pengolahan data: Kurangnya keterampilan dalam pengolahan data dapat menyebabkan kesalahan dalam pemilihan fitur. Kesalahan dalam pengolahan data dapat menghasilkan fitur-fitur yang tidak relevan atau bahkan menghasilkan hasil analisis yang salah.
Dalam rangka untuk berhasil pada tahap genetik, penting untuk memahami data dengan baik, menggunakan algoritma yang tepat, dan memiliki keterampilan dalam pengolahan data yang benar. Dengan melakukan hal ini, dapat membantu memastikan bahwa fitur-fitur yang relevan dan penting dipilih untuk analisis data dan menghasilkan hasil analisis yang akurat dan berguna.
Kegunaan Data Science dalam Penyelesaian Permasalahan di Bidang Lingkungan
Modeling data science dapat digunakan untuk membantu menyelesaikan permasalahan dalam bidang lingkungan, seperti:
- Pengelolaan sampah : Dengan memodelkan data produksi sampah dan mengidentifikasi faktor-faktor yang memengaruhi produksi sampah, dapat membantu dalam merancang strategi pengelolaan sampah yang efektif. Model ini dapat membantu dalam menentukan jenis-jenis sampah yang dapat didaur ulang, mengoptimalkan proses daur ulang, dan mengurangi jumlah sampah yang dihasilkan.
- Analisis perubahan iklim : Dengan memodelkan data iklim dan memperhitungkan faktor-faktor seperti emisi gas rumah kaca, suhu, curah hujan, dan lain-lain, dapat membantu dalam memahami perubahan iklim yang terjadi. Model ini dapat digunakan untuk memprediksi perubahan iklim di masa depan dan membantu dalam merancang kebijakan yang dapat mengurangi dampak perubahan iklim.
- Pengurangan emisi gas rumah kaca : Dengan memodelkan data tentang emisi gas rumah kaca dan mengidentifikasi faktor-faktor yang memengaruhi emisi tersebut, dapat membantu dalam merancang strategi pengurangan emisi yang efektif. Model ini dapat membantu dalam menentukan teknologi yang lebih efisien dan berkelanjutan untuk mengurangi emisi gas rumah kaca dan mengurangi dampak perubahan iklim.

Tinggalkan komentar